6.3.5.3.1. 初始化流程
6.3.5.3.1.1. probe和bind过程
为了约束初始化顺序,AICFB 为 component 的 master 设备,DE、DI 和 panel 为 slave 设备,component 框架保证 master 的初始化顺序在所有 slave 之后。各模块的初始化顺序如下:

图 6.35 显示模块的初始化顺序
其中:
master 调用 component_match_add() 接口声明一个 match 队列。
master 调用 component_master_add_with_match() 将自己注册进 component 框架。
slave 调用 component_add()完成 slave 注册。
各模块的 probe 顺序没有约束,设备的注册和声明在 probe 函数中进行。
每个子设备都要实现自己的 bind() 和 unbind() 接口(struct component_ops),当 match 队列中的模块都完成 probe 后,component 框架会调用模块的 bind() 接口。
各 slave 按 match 队列顺序执行 bind(),Component 框架保证 master 最后执行。
aicfb->bind() 主要完成 framebuffer 申请、fb 设备注册、使能 UI 图层、使能 panel 等动作。
6.3.5.3.1.2. 硬件时序要求
DE、DI、panel 三个硬件模块在初始化时有一些时序要求,包含先后顺序、延迟大小,主要约束来自于 panel 侧。 为了应对这样的硬件特性,驱动设计中使用 callback 方式来实现多个模块间的互相调用。
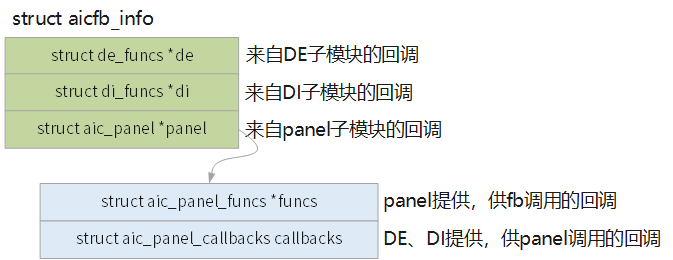
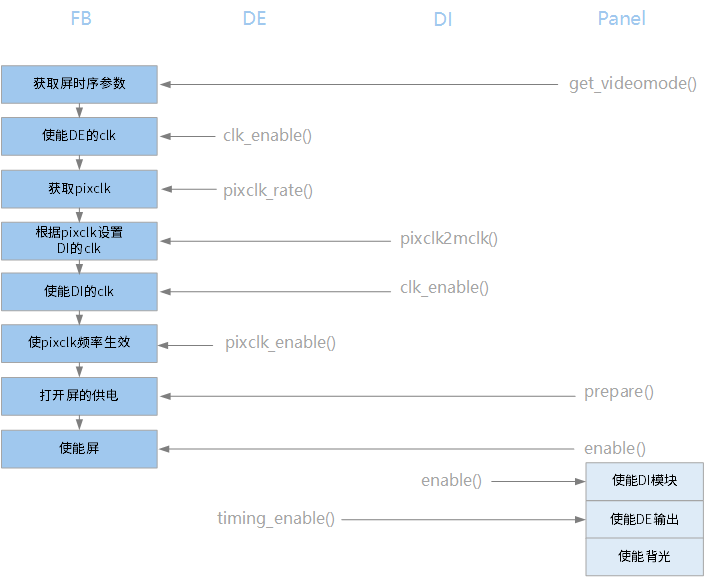
在fb的bind()中,会调用这些回调来完成初始化,如下图(其中关系比较绕的是 panel 初始化逻辑):
6.3.5.3.2. 预留内存管理流程
6.3.5.3.2.1. CMA
Linux-3.5 引入了一套 Contiguous Memory Allocator,简称 CMA,基于 DMA 映射框架为内核提供连续大块内存的申请和释放。CMA 主要思路是将预留内存纳入 DMA 映射管理,可以给系统内所有设备共享使用,这样就既解决了为 GPU、Camera、显示等图像处理类模块预留大块的连续内存,又解决了预留内存被空置的问题,提升内存使用率。
CMA 本身不是一套分配内存的算法,它的底层仍然要依赖伙伴算法系统来支持,可以理解为 CMA 是介于 DMA mapping 和内存管理之间的中间层。
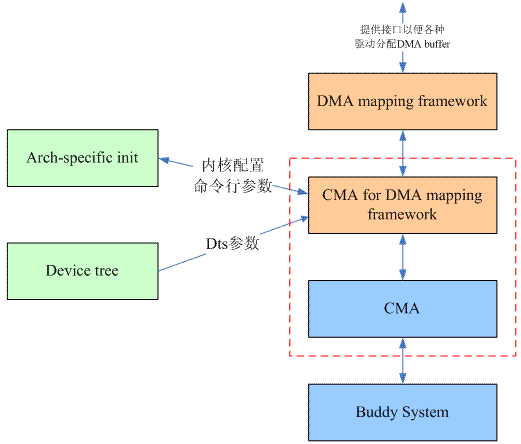
CMA的具体功能有:
在系统的启动过程中,根据内核编译配置、或者 DTS 配置将内存中某块区域用于 CMA,然后内核中其他模块可以通过 DMA 的接口 API 申请连续内存,这块区域我们称之为 CMA area。
提供 cma_alloc()和 cma_release()两个接口函数用于分配和释放 CMA pages。
记录和跟踪 CMA area 中各个 pages 的状态。
调用伙伴系统接口,进行真正的内存分配。
CMA 主要接口
CNA area 的声明
setup_bootmem() -> dma_contiguous_reserve(),定义在 kernel/dma/contiguous.c,其中有确定 CMA area size 的代码如下:
#ifdef CONFIG_CMA_SIZE_SEL_MBYTES selected_size = size_bytes; #elif defined(CONFIG_CMA_SIZE_SEL_PERCENTAGE) selected_size = cma_early_percent_memory(); #elif defined(CONFIG_CMA_SIZE_SEL_MIN) selected_size = min(size_bytes, cma_early_percent_memory()); #elif defined(CONFIG_CMA_SIZE_SEL_MAX) selected_size = max(size_bytes, cma_early_percent_memory()); #endif
然后会调用 dma_contiguous_reserve_area() -> cma_declare_contiguous() 去初始化 CMA 的配置参数。
小技巧
计算 CMA 内存大小的过程中,size_bytes 来源于内核编译配置中 CONFIG_CMA_SIZE_MBYTES,通过计算将 size 限定在 4MB 对齐。 参考 CMA配置 进行设置。
CMA 初始化
见 mm/cma.c 中的 cma_init_reserved_areas() -> init_cma_reserved_pageblock(),其中会设置 page 属性为 MIGRATE_CMA。
申请 CMA
使用 DMA 标准接口 dma_alloc_coherent() 和 dma_alloc_wc(),会间接调用 dma_alloc_from_contiguous()。
释放 CMA
使用 DMA 标准接口 dma_free_coherent()。
6.3.5.3.2.2. DMA-BUF
CMA 解决的是预留内存空闲期间如何给其他设备共享的问题,DMA-BUF 解决的是使用期间多个设备共享的问题、以及内核态和用户态如何共享内存的问题。DMA-BUF 可减少多余的拷贝,提升系统运行效率。
DMA-BUF 最初原型是s hrbuf,于 2011 年首次提出,实现了 “Buffer Sharing” 的概念验证。shrbuf 被社区重构变身为 DMA-BUF,2012年合入 Linux-3.3 主线版本。
DMA-BUF 被广泛用在多媒体驱动中,尤其在 V4L2、DRM 子系统中经常用到。
DMA-BUF vs ION
从 Linux-5.6 开始,DMA-BUF 正式合入了原来 ION 的 heap 管理功能,社区的主分支是打算抛弃 ION 了。在Linux-5.11,主分支已经删除了 drivers/staging/android/ion 代码,原因是“原厂对ION的支持在社区中不太活跃,很难持续更新ION”,而且ION还带来了几个ABI break。
ION 有大量的 heap 逻辑管理,而 DMA-BUF 的 heap 更多是分配接口上的管理(社区更容易接受);
ION 是生产一个字符设备 /dev/ion,而 DMA-BUF 为每个 heap 生成一个字符设备,便于用户态的heap区分和权限管理;
ION 限制最多32个 heap,DMA-BUF 没有这个限制;
DMA-BUF中实现了两个初始的 heap:system heap 和 cma heap,与原 ION 中的功能类似,但做了很大简化(为了方便社区 review),删掉原来 ION 中针对 system、cma 做过的一些优化,涉及 uncached buffers、large page allocation、page pooling和deferred freeing。 DMA-BUF 中的 CMA,只添加了default CMA 区域。原 ION 中的 CMA 是添加了所有 DMA 区域。
工作机制
为了解决各个驱动之间的 buffer 共享问题,DMA-BUF 将 buffer 与 file 结合使用,让 DMA-BUF 既是一块物理 buffer,同时也是个 Linux 标准 file。典型的应用框图如下:
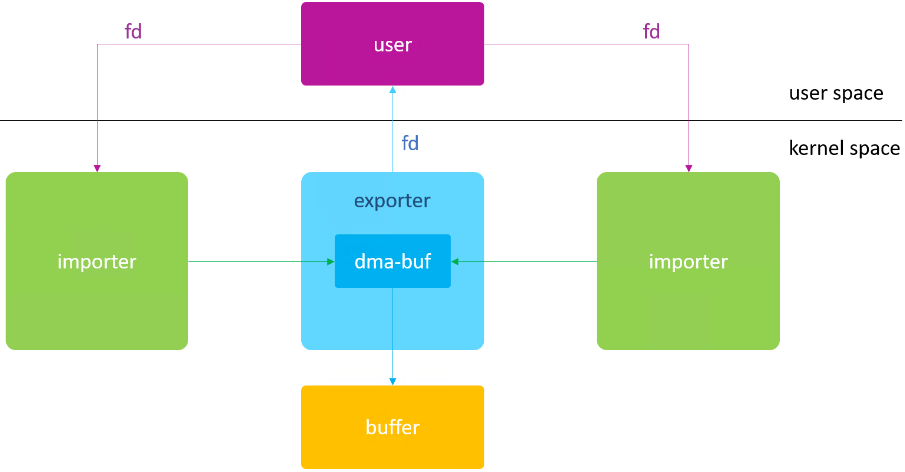
分配 buffer 的模块为 exporter,使用该 buffer 的模块为 importer。
DMA-BUF 支持连续物理内存、散列物理内存的 buffer 管理。ZX 平台目前只支持连续物理内存的 DMA-BUF。
主要接口
内核空间
- 作为 exporter
注册接口
dma_buf_export()- 作为 importer
获取buf的接口:
dma_buf_get,``dma_buf_attach()``,``dma_buf_map_attachment``。
用户空间
通过 ioctl 来管理 DMA-BUF。
基于 DMA-BUF 的 Video Layer buffer 管理
UI Layer的 buffer,由 driver 申请,通过 /dev/fb0 透传到用户态,用户态使用 mmap() 实现 buffer 共享。
但对于 Video Layer 的 buffer,情况有所不同,申请多大 buffer、多少个 buffer 都是由应用场景确定,所以应该是用户态发起申请。同时这个 buffer 还要满足物理连续的特性,DE 硬件才能用来做图层叠加处理。
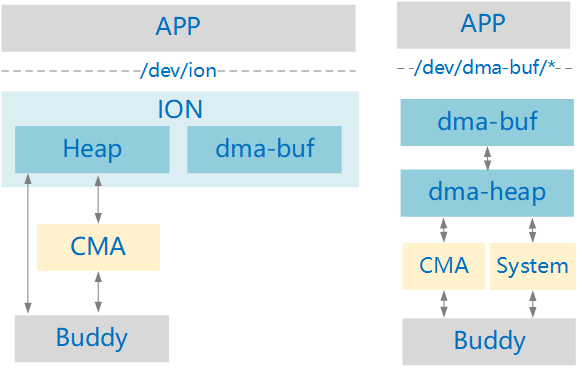
左图,是 ION 时代的使用方法,新版 Linux(Linux-5.6以后)的 DMA-BUF 已经支持了 heap 功能,从功能上完全可以替代 ION。对用户态来说,看到的差别不再是单一的 /dev/ion 设备节点,而是有多个 /dev/* 设备节点,比如 CMA heap 会生成 /dev/dma_heap/reserved,System heap 会生成 /dev/dma_heap/system。
使用 DMA-BUF 的情况下,APP 和 fb 驱动共享 buffer 的初始化流程如下图所示:
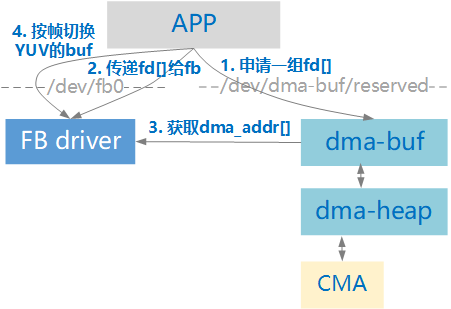
其中第3步的操作比较啰嗦,fb 驱动根据 APP 传来的一组fd[],逐个去向 DMA-BUF 模块申请以下资源:dma_buf -> attatch -> sg_table -> dma_addr_t,并将这组资源保存在本地(struct aic_de_dmabuf),用于释放 DMA-BUF。
这里面有一个假设:sg_table 中只有一个 sg。也就是说单个 DMA-BUF 必须是物理连续的,不能是多块 buf 拼起来的,否则物理地址 dma_addr_t 就不能代表多块 buf 的起始地址。
对于释放过程,APP需要先通知FB驱动要释放的fb[],然后再使用用户态文件接口close()逐个关闭fb[]。
小技巧
之所以申请“一组fd[]”,是因为video播放过程中为了边显示边解码,至少需要两套 Buffer 来实现乒乓效果(实际应用中为了更流畅,可能还需要申请多套 Buffer 构成循环 Buffer)。这里说的“一套Buffer”对应视频的一帧数据,而一帧视频数据往往分成YUV三个分量,每个分量在解码过程中是需要分别处理(对应DE寄存器中addr0、addr1、addr2),所以“一套Buffer”应该是 Y、U、V 共3个Buffer。对于乒乓结构的 Buffer,就需要申请 3*2=6 个DMA-BUF的fd。
UI Layer 的 buffer 申请,是直接调用通用 DMA 接口 dma_alloc_coherent(),最终在 CMA 内存中分配。这样并不影响 Video Layer的 buffer 走 DMA-BUF 申请,CMA 模块内部会处理好来自各种接口的 Buffer 申请。
6.3.5.3.3. Backlight
Backlight 使用内核中 pwm-backlight 背光驱动,代码见 linux-5.10driversvideobacklightpwm_bl.c。
panel 驱动可以通过 DTS 获取背光驱动的 device node , 然后 backlight API 控制背光。
backlight_enable() 使能背光
backlight_update_status() 对背光状态进行更新
backlight {
compatible = "pwm-backlight";
/* pwm node name; pwm device No.; period_ns; pwm_polarity */
pwms = <&pwm 0 1000000 PWM_POLARITY_INVERTED>;
brightness-levels = <0 10 20 30 40 50 60 70 80 90 100>;
default-brightness-level = <8>;
status = "okay";
};
panel_rgb {
compatible = "zx,aic-general-rgb-panel";
backlight = <&backlight>;
}; // 为节省篇幅,已省略无关配置
应用程序对背光进行操作:
echo 2 > /sys/class/backlight/backlight/brightness